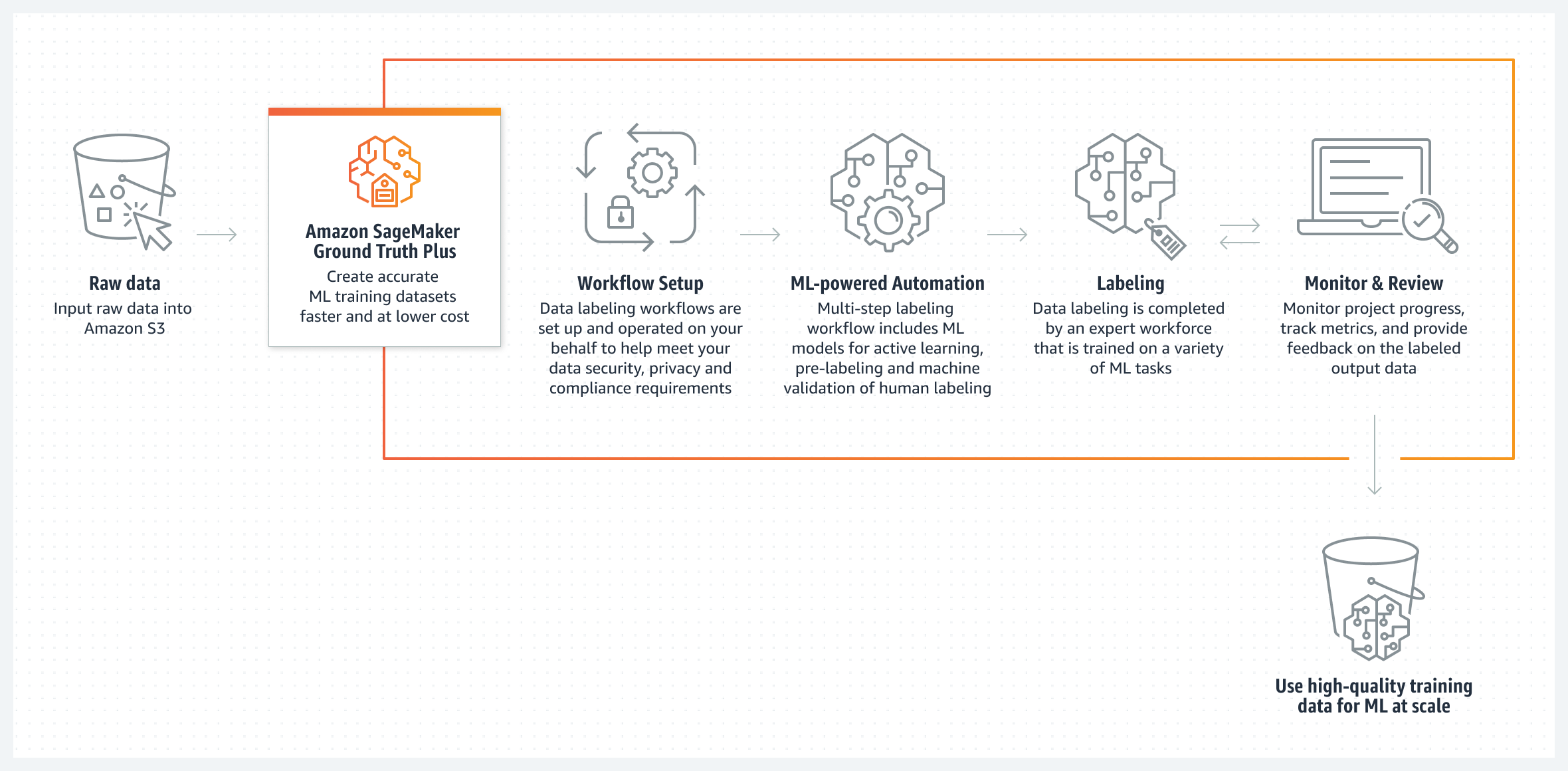
AWS đã thông báo rằng hiện tại người dùng có thể tạo dữ liệu tổng hợp được gắn nhãn với Amazon SageMaker Ground Truth.
SagaMaker Ground Truth là một dịch vụ giúp cho việc gán nhãn dữ liệu trở nên đơn giản và cho phép lựa chọn sử dụng các trình chú thích của con người thông qua các nhà cung cấp bên thứ ba, Amazon Mechanical Turk (hay MTurk là một thị trường cung cấp các dịch vụ cộng đồng giúp các cá nhân và doanh nghiệp dễ dàng thuê ngoài một lực lượng lao động phân tán để thực hiện các công việc cần thiết như: tham gia khảo sát, kiểm duyệt nội dung,…), hoặc nhân lực của bạn. Không nhất thiết phải thu thập dữ liệu thật, thay vào đó bạn có thể tạo dữ liệu tổng hợp được gắn thẻ theo cách khác. SageMaker Ground Truth có thể tạo ra hàng triệu hình ảnh tổng hợp được gắn nhãn tự động.
Quá trình tạo mô hình học máy (machine learning models) là lặp đi lặp lại, bắt đầu với việc chuẩn bị và thu thập dữ liệu, sau đó chuyển sang đào tạo mô hình (model training) và triển khai (deployment). Việc thu thập các bộ dữ liệu mở rộng, đa dạng và được gắn nhãn chính xác để đào tạo mô hình của bạn thường khó khăn và tốn thời gian, đặc biệt là giai đoạn đầu.
Với mục đích xây dựng bộ dữ liệu đào tạo (training datasets) toàn diện hơn cho các mô hình học máy (machine learning models) của bạn, việc kết hợp dữ liệu trong thế giới thực của bạn với dữ liệu tổng hợp (synthetic data) là rất hữu ích.
Bản thân dữ liệu tổng hợp được tạo ra bởi các quy tắc đơn giản, mô hình thống kê, mô phỏng máy tính hoặc các kỹ thuật khác. Giúp bạn có thể tạo ra một lượng lớn dữ liệu tổng hợp với các nhãn cực kỳ chính xác cho các chú thích trên hàng chục nghìn hình ảnh. Mức độ chi tiết rất nhỏ, chẳng hạn như cấp độ pixel hoặc sub-object level, và qua các phương thức có thể dùng để xác định độ chính xác của nhãn (label). Các phương thức hộp giới hạn (bounding box), đa giác, chiều sâu và phân đoạn (segment) là một số ví dụ.
Dữ liệu tổng hợp (synthetic data) là một giải pháp mạnh mẽ cho hai vấn đề khác nhau: giới hạn dữ liệu và rủi ro về quyền riêng tư. Khi thiếu dữ liệu được gắn nhãn, dữ liệu đào tạo (training data) có thể được bổ sung bằng dữ liệu tổng hợp (synthetic data) để giảm độ overfitting. Trong trường hợp bảo vệ quyền riêng tư, người quản lý dữ liệu có thể cung cấp dữ liệu được tạo ra thay vì dữ liệu thực tế theo cách đồng thời bảo vệ quyền riêng tư của người dùng và giữ tính hữu ích của dữ liệu gốc.
Bằng cách bổ sung tính đa dạng dữ liệu mà dữ liệu thật có thể thiếu, bạn có thể tạo ra các tập dữ liệu cân bằng và đầy đủ hơn bằng cách kết hợp dữ liệu thật của bạn với dữ liệu tổng hợp (synthetic data)
Với SageMaker Ground Truth, bạn có thể tự do thiết kế bất kỳ kịch bản hình ảnh nào với dữ liệu tổng hợp (synthetic data), bao gồm cả các trường hợp cạnh (edge case) có thể là thách thức để xác định và sao chép trong dữ liệu thật. Các biến thể có thể được thêm vào các đối tượng và môi trường xung quanh để phản ánh sự thay đổi ánh sáng, màu sắc, kết cấu, tư thế hoặc nền.
Nói cách khác, bạn có thể đặt hàng trường hợp sử dụng chính xác mà mô hình học máy (machine leaning models) của bạn đang được đào tạo. Amazon SageMaker Ground Truth synthetic data hiện đã available ở US East (N. Virginia). Dữ liệu tổng hợp được định giá trên cơ sở mỗi nhãn.
Theo: InfoQ