I. Phát biểu bài toán:
-
Mô tả:
Action recognition liên quan đến việc nhận biết, xác định vị trí và dự đoán các hành vi của con người trong video. Hay nói một cách dễ hiểu hơn, action recognition là bài toán phân loại video, cụ thể là phân loại hành động trong video.

-
- Input: Video
- Output: Predict class của video
Tuy bài toán của chúng ta được định nghĩa khá đơn giản, nhưng muốn xây dựng được 1 giải pháp hiệu quả, chúng ta phải giải quyết được các vấn đề sau:
-
- Vấn đề về dữ liệu: Chúng ta đã quá quen thuộc với các bài toán xử lý ảnh thông thường như: Image classification, Object detection, Object segmentation, … Đây là những tác vụ mà chỉ tập trung vào 1 hình ảnh, hay khi gọi trong 1 video thì nó chỉ là 1 frame riêng lẻ. Khi tăng level từ ảnh lên video, nó sẽ là bài toán ở cấp độ khó hơn. Video là 1 tập hợp nhiều frame, do đó input size sẽ lớn hơn các bài toán xử lý ảnh thông thường rất nhiều, chưa kể đến độ dài ngắn của video, chất lượng, độ phân giải của video đôi lúc cũng kém hơn ảnh rất nhiều. Việc thu thập video cũng mất rất nhiều thời gian, để training được model đủ tốt thì lượng data cần là vô cùng lớn. Một số bộ dataset thường được sử dụng hiện nay là: HMDB 51 (2011), UCF101 (2012), Sports1M (2014), Kinetics Family, AVA (2017), …
-
- Vấn đề về phương pháp: Muốn giải quyết bài toán action recognition, chúng ta cần trả lời được 2 câu hỏi tiên quyết: “Làm sao để mô hình hóa thông tin về thời gian trong video?” và “Làm sao để giảm được lượng tham số tính toán khi xử lý mà không ảnh hưởng đến chất lượng phân lớp?” – Do triển khai các mô hình xử lý video luôn sử dụng dung lượng tài nguyên tính toán cực kì lớn, nên đây là những câu hỏi nhất định phải giải quyết nếu muốn ứng dụng được vào thực tế.
-
Ứng dụng:
Action recognition có vai trò rất lớn trong nhiều bài toán thực tế như:
-
- Phân tích hành vi con người (human behavior analysis)
- Hỗ trợ tương tác giữa người và robot (human – robot interaction)
- Hỗ trợ các hệ thống gaming giải trí
-
Thách thức:
-
- Các hành động của con người không cố định (mỗi cây mỗi hoa, mỗi nhà mỗi cảnh :>).
- Nhận dạng hành động và chú thích lên video rất tốn công và không rõ ràng (khó xác định điểm bắt đầu và kết thúc của một hành động).
II. Một số hướng tiếp cận:
Trước khi Deep Learning phát triển, bài toán action recognition sử dụng phương pháp handcrafted features – để trích xuất đặc trưng của chuyển động trong video, sau đó áp dụng các bộ phân lớp như SVM để phân loại video. Dù kết quả cho thấy tương đối tốt, nhưng những phương pháp này cần chi phí tính toán quá lớn.
Các mô hình đã được xây dựng để giải bài toán action recognition theo thời gian:
 Các phương pháp này có thể chia thành những nhóm chính sau:
Các phương pháp này có thể chia thành những nhóm chính sau:
- CNN + RNN
Đây là các mô hình xử lý dạng chuỗi (do video chúng ta là chuỗi các frame liên tiếp nhau).
Các mô hình sẽ sử dụng phần đầu là các mạng CNN để trích xuất thông tin không gian từ frame (spatial information), tiếp đó các mạng RNN sẽ lấy input là các features này để đưa ra predict cuối cùng với hy vọng RNN có thể mô hình hóa được thông tin thời gian (temporal information) trong video.
- Two – stream networks
Kiến trúc này sử dụng 2 luồng khác nhau:
-
- Spatial information được chứa trong ảnh RGB
- Temporal information được chứa trong optical flow
Sau đó, kết quả sẽ được fusion từ 2 luồng và đưa ra predict cuối cùng.
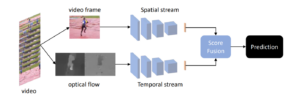
Optical flow có chi phí tính toán cao. Tuy nó giải quyết được vấn đề chồng chéo của đối tượng nhưng đối với các đối tượng hay vùng ảnh tương đồng thì lại hoạt động không tốt.
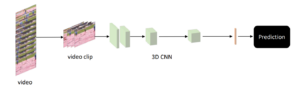
- 3D Convolution
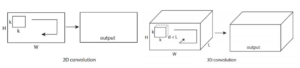
Thay vì sử dụng các input tensor 2 chiều thông thường như trong các bài toán xử lý ảnh, để cố gắng trích xuất các spatial information từ các frame thì phương pháp này gộp cả spatial information và temporal information lại để xử lý.
Nói một cách dễ hiểu, với một tập n frame có kích thước (height, weight) ta sẽ thu được 1 tensor với số chiều là (n, height, weight, 3). Sau đó, đưa tensor này qua các module 3D CNN đã được cung cấp sẵn.
- Skeleton-based
Việc phân loại hành động của con người dựa trên nhiều yếu tố, tuy nhiên tư thế của con người (human pose) vẫn là yếu tố quyết định của chuyển động.
Nhờ sự phát triển của các mô hình Pose estimation mà việc phân loại hành động sử dụng đầu vào là khung xương cơ thể người (skeleton) cũng được quan tâm nhiều hơn.
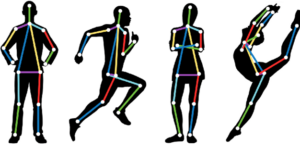
Việc sử dụng skeleton làm ‘spatial information’ giúp cho mô hình không phụ thuộc vào background và giảm được khối lượng tính toán đáng kể. Thông tin skeleton được trích xuất từ các mô hình pose estimation và được dùng làm input cho mô hình phân loại phía sau. Có thể kể đến một số mô hình pose estimation phổ biến như: Openpose, Alpha-Pose, YOLO-Pose, … Việc các mô hình pose estimation phát triển với độ chính xác cao và tốc độ xử lý tối ưu là cơ sở cho việc xây dựng mô hình Skeleton-based Action Recognition.
Trong bài viết này chúng ta sẽ cùng phân tích một nghiên cứu đang là SOTA trên tập NTU RGB+D: “Revisiting Skeleton-based Action Recognition” (PoseC3D). Mô hình PoseC3D là sự kết hợp giữa pose estimation và 3D-CNN cho bài toán nhận diện hành động.
Ảnh đầu vào (RGB) được đưa qua bộ pose estimation để trích xuất “2D Heatmaps for joints”. Các heatmap này được xếp lại và preprocess để tạo thành tensor 3D làm input cho mạng 3D-CNN. Ưu điểm của việc sử dụng joints heatmap là giúp cho mô hình không phụ thuộc vào background và tốc độ tính toán nhanh trong khi vẫn giữ được spatial information.

III. Hướng tiếp cận bằng SlowFast networks cho bài toán action recognition:
Để nâng cao hơn nữa hiệu quả của 3D CNN, các biến thể của nó bắt đầu xuất hiện và đặc biệt là SlowFast.
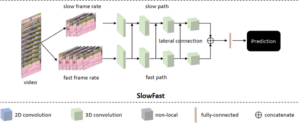
SlowFast gồm có 2 luồng fast pathway và slow pathway.
-
- Slow pathway hoạt động ở low frame rate để capture thông tin ngữ nghĩa (hay còn gọi là thông tin về không gian).
- Fast pathway hoạt động ở high frame rate để capture sự thay đổi của chuyển động (hay còn gọi là thông tin về thời gian).
Để kết hợp thông tin chuyển động giống như trong mạng hai luồng, SlowFast thông qua một kết nối lateral để hợp nhất các thông tin đã học theo từng con đường. Nhờ thông tin về thời gian từ fast pathway bổ sung cho nhánh slow pathway, hiệu quả tổng thể về không gian và thời gian của SlowFast được cải thiện.
Step-by-step to implementation SlowFast for action recognition:
- Cài đặt các thư viện cần thiết:
import torch
import torchvision
from torchvision import transforms as trn
import cv2
from PIL import Image
- Load model và gán id cho các label trên tập dữ liệu Kinetics 400 đã được training:
# Load model
model = torch.hub.load('facebookresearch/pytorchvideo', 'slowfast_r50', pretrained=True)
# ------------------------------------------------------------------------------
from typing import Dict
import json
import urllib
json_url = "https://dl.fbaipublicfiles.com/pyslowfast/dataset/class_names/kinetics_classnames.json"
json_filename = "kinetics_classnames.json"
try: urllib.URLopener().retrieve(json_url, json_filename)
except: urllib.request.urlretrieve(json_url, json_filename)
with open(json_filename, "r") as f:
kinetics_classnames = json.load(f)
# Create an id to label name mapping
kinetics_id_to_classname = {}
for k, v in kinetics_classnames.items():
kinetics_id_to_classname[v] = str(k).replace('"', "")
- Chuẩn bị & transform input để phù hợp với yêu cầu của model:
# Transform
def load_transform():
tf = trn.Compose([
trn.Resize((224, 224)),
trn.ToTensor(),
trn.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
return tf
transform = load_transform()
-
- Read video bằng opencv2 (link video: https://dl.fbaipublicfiles.com/pytorchvideo/projects/archery.mp4)
- Capture riêng lẻ 2 luồng frame: slow và fast
- Transform & stack 2 luồng frame lại thành input
V = cv2.VideoCapture('archery.mp4')
cnt = 32
list_frames=[]
list_frames2=[]
ret, frame = V.read()
while cnt > 0:
cnt -= 1
img = Image.fromarray(frame)
list_frames.append(img)
if cnt % 4 == 0:
list_frames2.append(img)
slow_pathway = list_frames2
fast_pathway = list_frames
fast = torch.stack([transform(frame)for frame in fast_pathway],1).unsqueeze(0)
slow = torch.stack([transform(frame) for frame in slow_pathway],1).unsqueeze(0)
inputs = [slow,fast]
- Get predictions:
preds = model(inputs)
post_act = torch.nn.Softmax(dim=1)
preds = post_act(preds)
pred_classes = preds.topk(k=5).indices[0]
# Map the predicted classes to the label names
pred_class_names = [kinetics_id_to_classname[int(i)] for i in pred_classes]
print("Top 5 predicted labels: %s" % ", ".join(pred_class_names))
- Result:
![]()
IV. Tài liệu tham khảo:
- A Comprehensive Study of Deep Video Action Recognition
- Video understanding
- Giới thiệu sơ qua bài toán nhận diện hành động của người trong video
- SlowFast networks for action recognition
V. Tác giả:
- Huỳnh Thị Mỹ Thanh – Data Science Intern @ P.SP CADS
- Nguyễn Công Hoan – Data Science Intern @ P.SP CADS

Comments 1