Giới thiệu
hello hello hello, mình là Doanh đây….
Bài viết này dành cho:
- Đã đọc Chapter 1 và muốn đi sâu hơn vào các phiên bản của YOLO.
- Có kiến thức cơ bản về Convolutional Networks.
Mở đầu
Ở bài blog trước là Đã quá YOLO ơi, chúng ta đã được giới thiệu các version của YOLO cũng như cùng đi qua sơ lượt về các cải tiến và sự khác nhau giữa các version của YOLO. Ở bài viết lần này, chúng ta cùng tìm hiểu rõ hơn bên trong version YOLOv1 nhé. Bắt đầu thôi nào…
YOLO v1: You Only Look Once: Unified, Real-Time Object Detection
Trước khi xuất hiện YOLO, các hệ thống object detection thường sử dụng 2 thành phần trong hệ thống: Đầu tiên là xác định khu vực có thể chứa vật thể (region proposal) trước khi đưa qua bộ phận phân loại để biết được vật thể đó là gì (classify). Nhận thấy việc dùng 2 bước này dẫn đến chậm và khó tối ưu vì các thành phần đều riêng lẻ và phải huấn luyện riêng biệt, Tác giả của YOLO đã đề xuất một phương pháp mới, đó là gộp chung 2 bước này lại thành 1. Với việc đưa 2 phần thành 1 mạng neural network duy nhất đã giúp cho model có thể tối ưu tốt hơn về hiệu suất và tăng tốc độ xử lý của toán bộ hệ thống. Đó cũng là lý do tên bài báo là “You Only Look Once” (YOLO) – bạn chỉ cần nhìn một lần là biết vật thể là gì và ở đâu.

Nhìn hình phía trên chúng ta có thể nhận thấy model rất đơn giản, nó chỉ là một Convolutional Network để có thể dự đoán được bounding box (bbox) và xác suất của class cho bbox đó. Với 1 luồng duy nhất để phát hiện vật thể, thì YOLO đã mang đến:
- Nhanh, hệ thống đạt tốc độ 45 fps (frames per second), và 150 fps trên Fast version. Với thông số này, thì YOLO đã nhanh gấp 90 lần so với model object detection trước đó là Fast R-CNN (tốc độ là 0.5 fps).
- Ngoài phát hiện được vật thể, thì YOLO còn nhìn thấy được tổng quan hình ảnh input. Với các hệ thống sử dụng 2 bước để phát hiện vật thể thì việc này là không thể, vì nó không thể nhìn được tổng quan của hình ảnh có gì.
- YOLO nhìn đối tượng một cách tổng quát, vì thế YOLO vẫn phát hiện được vật thể khi cho YOLO học hình ảnh ở tự nhiên và có thể dự đoán vật thể trên ảnh nghệ thuật.
- Có một hạn chế, là khi so về độ chính xác thì YOLO vẫn còn thấp hơn so với các model SOTA (State-of-the-Art) trước đó.
Hệ thống detection mới

YOLO chia ảnh đầu vào thành S x S ô nhỏ. Nếu tâm của object nằm trong 1 ô lưới nào đó, thì ô đó có nhiệm vụ phát hiện đối tượng đó.
Mỗi 1 ô trong S x S ô lưới, có nhiệm vụ dự đoán ra Β là bounding boxes (bbox) và confidence cho các box đó. Mỗi B được dự đoán sẽ có 5 thông tin: box(x,y,w,h) và confidence, với các giá trị:
- x: trọng tâm đối tượng theo tọa độ x.
- y: trọng tâm của đối lượng theo tọa độ y.
- w: độ rộng của vật thể, tỉ lệ với kích thước của ảnh đầu vào.
- h: chiều cao của vật thể, tỉ lệ với kích thước của ảnh đầu vào.
- confidence: độ tin cậy, xác suất đó là vật thể.
Độ tin cậy confidence được tính bằng cách so sánh thông tin predict ra và thông tin được label, được định nghĩa bằng công thức:
![]()
- Pr(Classi| Object): xác suất của mỗi class cho ô.
- Pr(Object): xác suất có vật thể trong ô.
- IOU: phần giao nhau của bbox predict và bbox được label. Bạn có thể tìm hiểu rõ hơn IoU ở bài IoU là gì?
YOLO dùng dataset PASCAL VOC để đánh giá model, với tập dataset này thì Tác giả đã chọn S = 7, B = 2, tập VOC có C = 20 class, như vậy chúng ta sẽ có output của model YOLO là: S x S x (B*5 + C) = 7x7x30 tensor.
Lưu ý: trong 1 ô lưới thì chỉ có tâm của 1 object, ví dụ 2 object cùng có tâm trên 1 ô lưới, thì chỉ phát hiện được 1 object có score cao nhất. Đây cũng là điểm yếu của YOLO v1, vì chỉ có tối đa 7×7=49 object được phát hiện trong 1 ảnh.
Network Design
Được lấy cảm hứng từ model GoogleNet – model dùng để phân loại hình ảnh, các Tác giả của YOLO đã thiết kế một network có 24 layers convolutional để trích xuất feature trên mỗi ảnh đầu vào, và tiếp theo sau là 2 layer fully connected có nhiệm vụ dự đoán ra xác suất và tọa độ của từng object có trong ảnh.
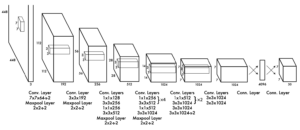 Về cơ bản, YOLO chứa 3 loại layer: Convolutional, Maxpool, và Fully Connected. Tác giả của YOLO đã kế thừa kiến trúc của GoogleNet, nhưng thay thế inception modules của GoogleNet bằng module chứa 1×1 convolutional layer kết hợp với 3×3 convolutional layer (ý tưởng dựa trên paper Network In Network), mục đích của 1×1 convolutional layer là để giảm số chiều của feature.
Về cơ bản, YOLO chứa 3 loại layer: Convolutional, Maxpool, và Fully Connected. Tác giả của YOLO đã kế thừa kiến trúc của GoogleNet, nhưng thay thế inception modules của GoogleNet bằng module chứa 1×1 convolutional layer kết hợp với 3×3 convolutional layer (ý tưởng dựa trên paper Network In Network), mục đích của 1×1 convolutional layer là để giảm số chiều của feature.
Với mục đích nhanh hơn nữa, một biến thể của của YOLO v1 dùng để tăng tối đa tốc độ cho việc phát hiện đối tượng là Fast YOLO cũng được giới thiệu. Khác với YOLO thì Fast YOLO chỉ sử dụng 9 layer convolutional thay vì 24 layer convolutional, kết hợp với dùng filter size nhỏ hơn đã giúp tốc độ infer của Fast YOLO đạt được 155 fps.
Trên các layer convolutional sử dụng Leaky ReLU để làm activation function trên toàn bộ network, ngoại trừ lớp cuối cùng cần phân loại thì network sử dụng linear activation function.
Loss function
Loss function của YOLO được định nghĩa theo công thức ở dưới, thoạt nhìn thì khá là dài dòng và phức tạp, nhưng bạn đừng lo, nó rất dễ hiểu.

YOLO sử dụng Sum-Squared Error (SSE) để tính loss của giá trị predict và ground truth. Tác giả của YOLO nghĩ rằng SSE giúp việc tối ưu dễ dàng hơn, nhưng việc này đồng thời cũng không đúng với mục tiêu là tối đa hóa việc trung bình độ chính xác, vì thế Tác giả còn thêm 2 trọng số vào hàm loss là λcoord và λnoobj . Cụ thể loss của YOLO là tổng của 5 loss thành phần, theo thứ tự từ trên xuống:
- Loss của tâm (x,y) của bbox được predict và bbox được label (ground-truth),
- Loss của chiều dài và rộng (h,w) của bbox được predict và bbox được label (ground-truth),
- Loss của confidence score khi có object trong ô (cell),
- Loss của confidence score khi không có object trong ô (cell),
- Loss của xác suất tại ô có object.
Ký hiệu trong hàm loss:
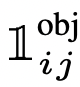 = 1 khi có object; và = 0 khi không có object.
= 1 khi có object; và = 0 khi không có object.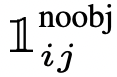 = 1 khi không có object, và = 0 khi có object.
= 1 khi không có object, và = 0 khi có object.
Loss (1): Loss của tâm object được predict và tâm object đã label
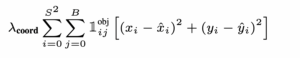
- Hàm loss này có chức năng tính toán loss giữa tâm vật thể (xi, yi) được dự đoán, và tâm vật thể (xi, yi) được label (ground truth). Loss được tính cho tất cả 49 ô, YOLO predict ra 2 bbox cho mỗi một ô lưới, nhưng chỉ 1 trong 2 bbox có IoU cao hơn so với label là được lựa chọn để tính loss.
- Sau khi tính loss cho tâm của object thì một trọng số λcoord = 5 được nhân vào để kéo bbox được dự đoán gần với ground truth hơn.
- Cuối cùng, được thêm vào để cho biết có object ở ô đang xét hay không.
Loss (2): Loss của chiều dài và chiều rộng (h,w) của bbox được predict và bbox được label (ground-truth)
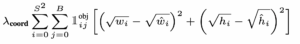
- Loss (2) thì tương tự như loss (1), nhưng ở đây được tính dựa trên chiều dài và chiều rộng của bbox.
- Để cân bằng khi tính loss giữa các bbox nhỏ và các bbox lớn, thì loss đã được lấy căn bậc hai của chiều dài và chiều rộng thay vì trực tiếp chiều dài và chiều rộng.
Đối với các bbox nhỏ, sự khác biệt về chiều rộng vài chục pixel sẽ đáng kể đến mức nó có thể bỏ sót đối tượng hoàn toàn. Tuy nhiên, đối với các bbox lớn chiếm một nửa hình, sự chênh lệch vài chục pixel có thể chỉ cắt bỏ một phần nhỏ của object. Đó là lý do mà Tác giả đã lấy căn bậc hai thay vì tính toán như bình thường.
Loss (3): Loss của confidence score khi có object trong ô (cell)
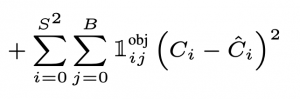
- Khi có object =1, hàm loss sẽ được tính giữa confidence score của predict và confidence score của label.
- Confidence score của predict được YOLO đưa ra.
- Confidence score của label là IoU của bbox predict và bbox label.
Loss (4): Loss của confidence score khi không có object trong ô (cell)
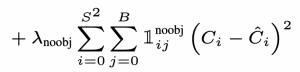
- Khi
 và
và  thì lúc này Loss (3) sẽ bằng 0.
thì lúc này Loss (3) sẽ bằng 0. - Tham số λnoobj được thêm vào với giá trị 0.5 với mục đích giảm sự ảnh hưởng của các ô không có object, vì số lượng ô không có object chiếm đa số trong hình.
Loss (5): Loss của xác suất tại ô có object
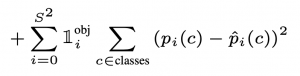
- Phần cuối cùng của loss là tính xác suất cho từng class trong dataset.
- Với mỗi ô, nếu object xuất hiện trong ô, thì loss sẽ được tính cho cả 20 class có trong dataset PASCAL VOC.
Benchmarks
Ở các phần phía trên chúng ta đã đi qua chi tiết model YOLO, bây giờ chúng ta cùng xem những cải tiến như thế, thì kết quả sẽ là như nào so với các model trước đó.

Ở Table 1, khi so sánh với các hệ thống Real-Time detector khác trên tập dataset Pascal VOC, thì cả YOLO và Fast YOLO đều cho thấy sự vượt trội về độ chính xác và tốc độ, gần như là gấp đôi.
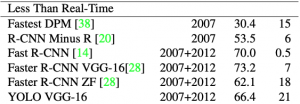
Ở Table 2, khi so sánh với các hệ thống không Real-Time detector. Faster R-CNN hiện vẫn đang có độ chính xác tốt nhất, nhưng chỉ có tốc độ là 7 FPS, còn YOLO với backbone là VGG-16 thì có độ chính xác thấp hơn 3.6 mAP, nhưng đạt được tốc độ là 21 FPS (đủ để thực thi trong hệ thống real-time).
Inference

Để cho thấy được sự tổng quát hóa của YOLO, thì Tác giả đã chạy phát hiện vật thể trên hình ảnh tự nhiên và cả tác phẩm nghệ thuật. Kết quả hầu hết là chính xác mặc dù có phát hiện ra một người là một chiếc máy bay 🙂
Limitations of YOLO
- YOLO chỉ có thể phát hiện tối đa 49 object trong một ảnh.
- Vì mỗi ô chỉ dự đoán hai bbox và chỉ có thể có một class, nên nếu có 2 object trong 1 ô thì cũng chỉ trả kết quả cho một object duy nhất, object có score cao hơn.
- Model khó phát hiện các object có kích thước nhỏ.
Conclusion
Mặc dù có những giới hạn nhất định trong hệ thống như được kể ra ở trên, nhưng YOLO đã có những cống hiện thực sự đáng ghi nhận. Việc định nghĩa ra được một phương pháp phát hiện đối tượng mới đã mở ra một chuỗi các bài báo liên quan, mà được kế thừa từ ý tưởng YOLO này.
Đến thời điểm hiện tại, chỉ cần bạn search “YOLO” trên github, thì sẽ có đến tận 33,195 repository results được xuất hiện.
Và chúng ta đã đi qua bài YOLO đầu tiên, hẹn gặp lại bạn ở các Paper Reading kế tiếp nhé, nhớ để lại ý kiến nếu bạn có thắc mắc gì về YOLO ở bên dưới nha.
Reference
[Paper] You Only Look Once: Unified, Real-Time Object Detection
Understanding a Real-Time Object Detection Network: You Only Look Once (YOLOv1)
Apply vào CADS tại đây
