Giới thiệu
hello hello hello, mình là Doanh đây….
Bài viết này dành cho:
- Người biết code.
Mở đầu
Bài toán Phát hiện vật thể (Object detection) trong thị giác máy tính hiện đang được ứng dụng rất nhiều trong các thiết bị thông minh trên thế giới. Từ phát hiện sản phẩm lỗi trong công nghiệp, đến các camera giám sát, hay nổi bật như camera điểm danh tại công sở… Với nhu cầu và tính cần thiết của bài toán này, mà nhiều nhà nghiên cứu đã và đang phát triển các thuật toán để làm cho việc phát hiện vật thể trở nên nhanh và chính xác hơn.
Từ khi paper YOLO (You Only Look Once: Unified, Real-Time Object Detection) xuất hiện vào năm 2016 thì nó đã tạo sự chú ý đáng kể từ cộng đồng nghiên cứu nhờ vào: dễ sử dụng (end-to-end) và tốc độ chạy nhanh (real-time). Sau khi version đầu tiên vào 2016 thì ông Joseph Redmon – tác giả chính của YOLO, đã phát triển thêm 2 version mạnh hơn là YOLO-v2 vào năm 2017 và YOLO-v3 vào năm 2018. Ngoài các version từ chính cha đẻ YOLO thì sau này còn có các nhà nghiên cứu khác cũng đã cải tiến và phát triển theo mục tiêu của các tác giả, và hiện chúng ta có: YOLO-v4, YOLO-v5, PP-YOLO…
Blog đợt này chúng ta sẽ cùng tìm hiểu YOLO qua các version? tại sao nó lại có nhiều phiên bản như vậy? và cách sử dụng một cách đơn giản như nào nhé. Ak, có nhiều người nghe YOLO thì sẽ nhầm tưởng qua YOLO – You Only Live Once ^^ không nhé các bạn, nó là YOLO – You Only Look Once – chúng ta chỉ nhìn một lần là phát hiện được vật thể nhé.
Thách thức
Với các bài toán điểm danh hay là phát hiện sản phẩm lỗi thì thử thách lớn nhất là tốc độ phải nhanh, và thật chính xác…
- Tốc độ nhanh: Điều quan trọng khi áp dụng một mô hình vào thực tế chính là tốc độ xử lý phải đáp ứng được thời gian thực.
- Độ chính xác: Độ chính xác cũng là một điều cực kỳ quan trọng trong hệ thống. Ví dụ sự sai sót trong hệ thống cửa tự động nhận dạng khuôn mặt là điều không được phép.
Để thấy được tốc độ và hiệu suất thì paper YOLO có một bảng so sánh [Bảng 1]:
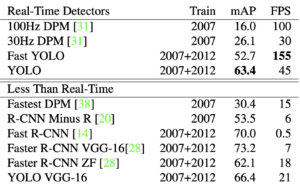
Bảng 1 cho thấy:
- Fast YOLO là model nhanh nhất và chính xác gấp đôi so với các model khác.
- YOLO chính xác hơn 10 mAP so với phiên bản Fast YOLO trong khi tốc độ vẫn cao hơn.
Các phiên bản của YOLO
Sự thành công YOLO đã thúc đẩy nhiều tổ chức và cá nhân đi sâu vào nghiên cứu và phát triển, chúng ta cùng điểm qua YOLO qua các version nhé.
YOLO v1 – You Only Look Once: Unified, Real-Time Object Detection
YOLO phiên bản đầu tiên được viết trên framework Darknet, một framework được viết với ngôn ngữ C++. Các phiên bản YOLOv1, YOLOv2, YOLOv3 và YOLOv4 đều sử dụng framework Darknet này cho việc huấn luyện model và inference.
Với các model cũ trước khi có YOLO, để phát hiện một vật thể chúng ta phải đi qua 2 bước (two-stage): Đầu tiên, xác định các vùng quan tâm (bounding boxes) – nơi chứa vật thể; tiếp theo, từ vùng quan tâm sẽ tìm ra được id của object.
Còn với YOLOv1, model kết hợp việc phát hiện vị trí của vật thể trong hình và tìm id của vật thể trong cùng 1 bước (end-to-end), cách làm như thế này được gọi là single stage.

YOLO v2 – YOLO9000: Better, Faster, Stronger
YOLOv2 được publish vào năm 2017.
Điểm yếu của YOLOv1:
- Độ chính xác kém hơn so với các mô hình Region-based detector (kỹ thuật sử dụng two-stage).
- Recall thấp, khả năng phát hiện bị thiếu/sót các đối tượng.
- Dự đoán tối đa một object trong 1 cell, tối đa 49 object.
Để cải thiện các điểm yếu của YOLOv1 thì YOLOv2 đã có một số cải tiến:
- Batch Normalization( BN): thêm BN vào tất cả các lớp chập.
- Bộ phân loại phân giải cao (High Resolution Classifier).
- Phát hiện nhiều đối tượng trong một ô lưới (gird cell).
- Anchor Boxes.
- Darknet19.
Với các cải tiến này, YOLOv2 đã tăng mAP từ 63.4 lên 78.6 so với YOLOv1 (độ chính xác và sai sót ít hơn), mà chỉ phải giảm FPS từ 45 xuống 40 (tốc độ chạy của model).
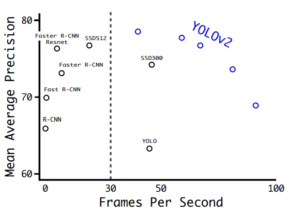
Từ hình trên cho thấy YOLOv2 có hiệu quả và tốc độ tốt hơn các model trước đó.
YOLOv3: An Incremental Improvement
YOLOv3 được publish vào năm 2018. YOLOv3 đã thực hiện một loạt các thay đổi nhỏ về thiết kế để làm cho hệ thống chạy tốt hơn, với một số thay đổi:
- Darknet53
- Nhận dạng ở các tỉ lệ ảnh khác nhau:
- YOLOv1 ô lưới ở: 7×7
- YOLOv2 ô lưới ở: 13×13
- YOLOv3: nhận dạng 3 lần trên 1 kích thước ảnh, với input 416×416:
- Conv 82: SxS = 13×13
- Conv 94: SxS = 26×26
- Conv 106: SxS = 52×5
Với những thay đổi này, YOLOv3 đã chạy nhanh hơn đáng kể so với các phương pháp khác với hiệu suất tương đương.

YOLOv4: Optimal Speed and Accuracy of Object Detection
Sau khi phát hành YOLOv3, Joseph Redmon không còn nghiên cứu thị giác máy tính. Các nhà nghiên cứu như Alexey Bochkovskiy và Glenn Jocher đã tiếp tục và phát triển lên YOLOv4 và YOLOv5.
YOLOv4 publish vào năm 2020, YOLOv4 đã có những cải tiến đặc biệt giúp tăng độ chính xác và tốc độ tốt hơn, một số cải tiến như chia cấu trúc của model thành bốn phần:
- Backbone(Xương sống): Trích xuất đặc trưng.
- Neck (phần cổ): Tổng hợp đặc trưng.
- Dense prediction (dự đoán dày đặc): Sử dụng các one-stage-detection như YOLO hoặc SSD.
- Sparse Prediction (dự đoán thưa thớt): Sử dụng các two-stage-detection như RCNN.

YOLOv5
YOLOv5 được công bố năm 2020 bởi Glenn Jocher, là model đầu tiên trong “gia đình YOLO” không publish paper, và model này cũng đang được cải thiện cũng như cho ra nhiều phiên bản để trên repo YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite.

YOLOv5 là một model open-source được bắt đầu bởi tổ chức Ultralytics, YOLOv5 cũng được khá nhiều nhà nghiên cứu đóng góp vào sự phát triển của model, đến thời điểm hiện tại thì repo đã được 27,2k star và đã có 242 người đóng góp vào repo.
Các phiên bản khác
Ngoài các version được lấy tên chính thức là YOLO, thì cũng có nhiều nghiên cứu phát triển model từ YOLO và đạt được những thành công nhất định như:
- PP-YOLO: được công bố vào năm 2020 bởi Baidu, vượt qua các chỉ số hiệu suất của YOLOv4 trên tập dữ liệu COCO. Từ “PP” là viết tắt của “PaddlePaddle”, một framework của Baidu (tương tự như TensorFlow của Google).
- Scaled YOLOv4: được công bố năm 2020 bởi Chien-Yao Wang và cộng sự. Model đã mở rộng kích thước của network trong khi vẫn duy trì cả độ chính xác và tốc độ của YOLOv4.
- PP-YOLOv2, PP-YOLOe: cả 2 phiên bản này đều được nâng cấp từ PP-YOLO do chính Baidu phát triển. 2 model này đã cải thiện và tăng tốc độ cũng như hiệu suất của model.
Sử dụng YOLO vào phát hiện vật thể
Đến thời điểm hiện tại thì YOLO đã chứng minh được hiệu quả cũng như tốc độ của nó vào các hệ thống AI. Bây giờ chúng ta cùng thử chạy model YOLOv5 để phát hiện vật thể qua các hướng dẫn bên dưới nhé.
Step 1: Cài đặt môi trường:
Yêu cầu của hệ thống cần có Python>=3.8 với PyTorch>=1.7
Để cài đặt các phụ thuộc cần cho YOLOv5 chúng ta chạy lệnh:
pip install -qr https://raw.githubusercontent.com/ultralytics/yolov5/master/requirements.txt
Step 2: chạy hệ thống phát hiện vật thể trong ảnh:
Chúng ta chạy model YOLOv5s đã được train trước đó, bây giờ chỉ cần chạy để phát hiện vật thể.
import torch
# Model
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True)
# Images
imgs = ['https://ultralytics.com/images/zidane.jpg'] # batch of images
# Inference
results = model(imgs)
# Results
results.print()
results.save() # or .show()
results.xyxy[0] # img1 predictions (tensor)
results.pandas().xyxy[0] # img1 predictions (pandas)
# xmin ymin xmax ymax confidence class name
# 0 749.50 43.50 1148.0 704.5 0.874023 0 person
# 1 433.50 433.50 517.5 714.5 0.687988 27 tie
# 2 114.75 195.75 1095.0 708.0 0.624512 0 person
# 3 986.00 304.00 1028.0 420.0 0.286865 27 tie
Và đây là kết quả:
Tổng kết
YOLO là một model khá mạnh và cộng đồng rộng lớn, các kỹ thuật và công nghệ luôn được phát triển, để cùng đi sâu hơn và cập nhật tin tức các vesion của YOLO, mời bạn theo dõi tiếp các bài mới của blog nhé!
Reference
- [yolo 1] https://arxiv.org/pdf/1506.02640.pdf
- [yolo 2] https://arxiv.org/pdf/1612.08242.pdf
- [yolo 3] https://arxiv.org/pdf/1804.02767.pdf
- [yolo 4] https://arxiv.org/pdf/2004.10934.pdf
- [yolo 5] https://github.com/ultralytics/yolov5
Comments 2