Cao Nguyễn Minh Trang, Võ Nhật Thịnh, Phan Võ Phương Tùng
Gần đây, ChatGPT được nhắc đến rất nhiều trên khắp các phương tiện truyền thông đại chúng. Nhờ vào kho kiến thức khổng lồ đã học được, ChatGPT có thể trả lời lưu loát hầu như mọi câu hỏi về bất cứ lĩnh vực nào. Bài viết ngày hôm nay sẽ mang đến cái nhìn chi tiết về thuật toán đứng sau sự thành công của ChatGPT, từ đó giúp bạn đọc hiểu hơn và phần nào đánh giá được độ tin cậy của siêu chatbot này.
Làm quen với ChatGPT
ChatGPT (Chat Generative Pre-training Transformer) là một chatbot do OpenAI phát triển, hiện chạy trên nền tảng đám mây Azure của Microsoft [1]. ChatGPT hoạt động dựa trên mô hình xử lý ngôn ngữ tự nhiên NLP (Natural Language Processing). Khi một câu hỏi được gửi đến ChatGPT, mô hình sẽ tiến hành phân tích và tìm kiếm trong kho kiến thức đã “học” để đáp lại một cách hợp lý nhất [1].
Tuy mới ra mắt vào tháng 11 năm 2022 nhưng ChatGPT đã vượt mặt tất cả những ông lớn công nghệ khác khi cán mốc cán mốc 100 triệu người dùng chỉ sau 2 tháng ra mắt [2]. Ngoài việc giúp người dùng trả lời một cách lưu loát và chính xác câu hỏi đến từ nhiều lĩnh vực như triết học, toán học, thậm chí lập trình, sáng tác,… ChatGPT còn được cho là vô cùng lịch sự khi được yêu cầu đưa ra nhận xét về phụ nữ. Chẳng hạn khi được hỏi về việc giữa Thúy Kiều và Thúy Vân thì ai đẹp hơn, ChatGPT đã trả lời rằng cái đẹp chỉ mang tính tương đối, và mỗi người đều có những nét phẩm chất đáng quý riêng nên đánh giá họ chỉ dựa trên ngoại hình là thiếu sót. Thật là có phẩm chất của một gentleman.

Hình 1. Trò chuyện với ChatGPT
Mới đây, ChatGPT còn được cho là có thể hỗ trợ con người tối ưu hóa đời sống tình cảm. Cụ thể hơn, khi một thành viên trong nhóm tâm sự với ChatGPT về nỗi khổ tâm khi yêu hai người cùng một lúc, quân sư tình yêu ChatGPT còn đưa ra những lời khuyên vô cùng sâu sắc và trải đời như sau.
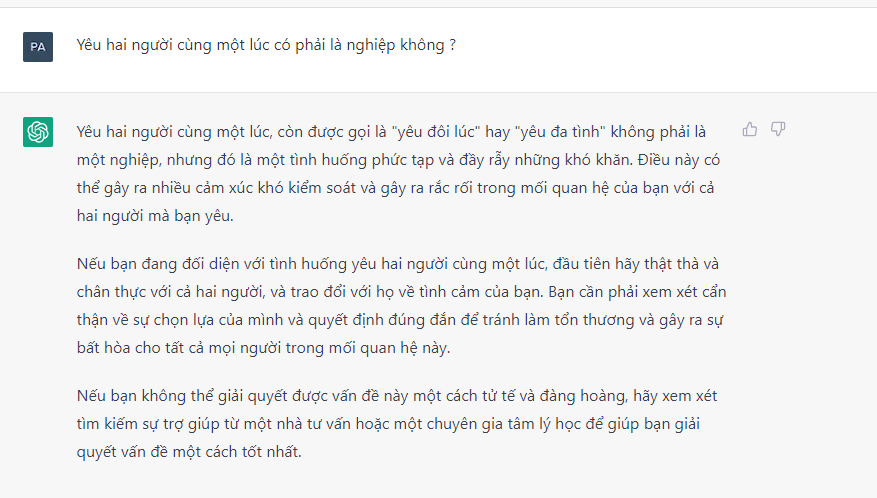
Hình 2. Tâm sự lúc 0h cùng ChatGPT
Vậy, yêu hai người liệu có phải là nghiệp không, và ta có thể tin tưởng vị quân sư tình yêu cùng những lời khuyên mà hắn dành cho chúng ta hay không? Bài viết dưới đây sẽ trình bày toàn bộ cấu trúc của thuật toán đứng sau ChatGPT, từ đó giúp người đọc đánh giá được độ “uy tín” của người bạn biết tuốt này.
Thuật toán RLHF
Có thể nhận thấy, đa số các câu trả lời của ChatGPT ngoài việc lưu loát và chính xác thì còn chân thật như thể người dùng đang được trò chuyện với một con người. Sự thành công này đến từ thuật toán RLHF (Reinforcement Learning from Human Feedback), nghĩa là học tăng cường từ phản hồi của người dùng. Thuật toán này giúp cho ChatGPT vừa có thể học từ những nguồn kiến thức sẵn có như một mô hình học giám sát (supervised learning), vừa có thể trau chuốt cho câu trả lời trở nên trơn tru nhờ những đánh giá của con người trong mô hình học tăng cường (reinforcement learning).
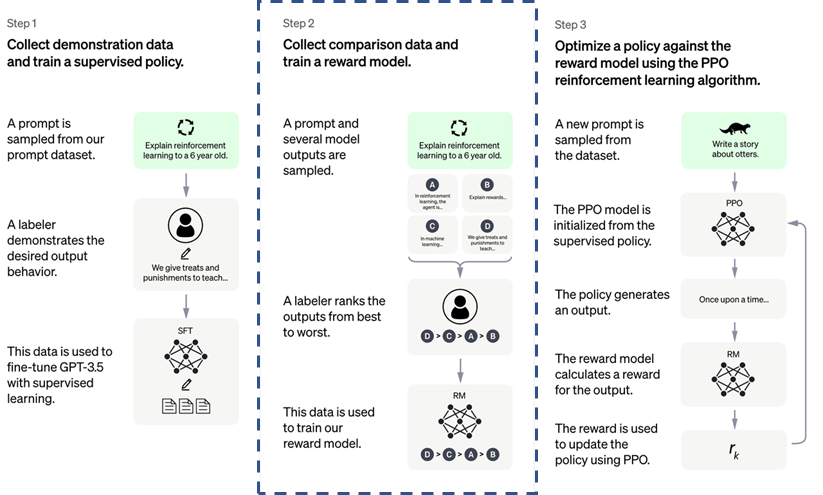
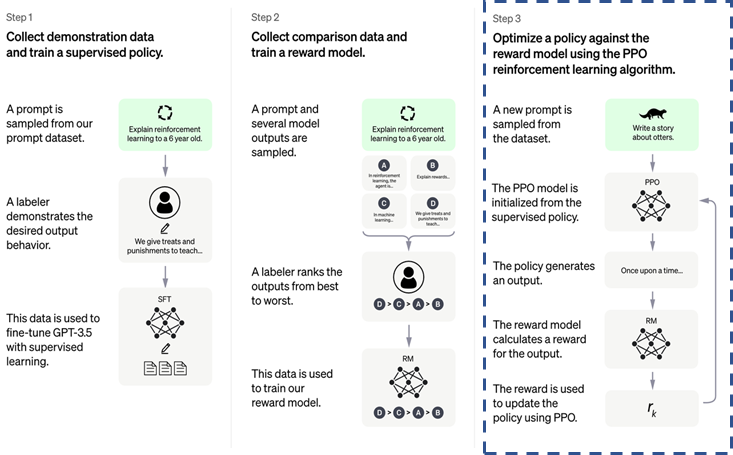
Cụ thể hơn, thuật toán RLHF được triển khai trong ChatGPT theo 3 bước [3], được minh họa bằng hình dưới đây:

Hình 3. Ba bước của thuật toán RLHF
- Ở bước 1, ChatGPT sử dụng mô hình xử lí ngôn ngữ tự nhiên GPT-3 làm nền tảng, bên cạnh đó sử dụng những dữ liệu được thu thập từ rất nhiều nguồn để tiếp tục tinh chỉnh (fine-tuning), để từ đó sinh ra mô hình GPT-3.5 hay SFT model.
- Sau khi có được mô hình GPT-3.5, ở bước 2, SFT model được sử dụng để sinh ra rất nhiều câu trả lời (response) cho cùng một mẫu dữ liệu (prompt). Tất cả các response này sau đó sẽ được con người đánh giá trên nhiều tiêu chí khác nhau, từ đó xây dựng mô hình đánh điểm (reward model).
- Cuối cùng, sau khi đã có được SFT model và reward model, phương pháp tối ưu PPO (proximal policy optimization) sẽ được thực hiện, với mục đích cân bằng câu trả lời của ChatGPT giữa nguồn kiến thức có sẵn (ở bước 1) và những đánh giá của con người (ở bước 2).
Bước 1: Huấn luyện SFT model
OpenAI muốn hướng tới việc xây dựng một chatbot có thể thực hiện nhiều chức năng như biên dịch (translation), Q&A, phân tích cảm xúc (sentiment analysis) hay nhận diện tài liệu (document classification), … Tuy nhiên, dữ liệu để huấn luyện cho từng model của từng tác vụ nói trên tốn rất nhiều tài nguyên. Giải pháp của OpenAI lúc này là sử dụng một pre-trained model đã được huấn luyện sẵn. Như vậy OpenAI chỉ cần thực hiện fine-tuning model này để có thể ứng dụng cho các tác vụ khác.
Và OpenAI đã lựa chọn GPT-3 (Generative Pre-trained Transformer 3) để thực hiện fine-tuning. Đây là một mô hình có khả năng tạo ra (generate) văn bản, được phát triển bởi chính OpenAI trong giai đoạn đầu của công ty này.
GPT-3
GPT-3 được xây dựng dựa trên cấu trúc mạng neural Transformer. Điều đặc biệt ở Transformer là nó đọc văn bản hai chiều cùng một lúc và sử dụng attention score để tính độ liên quan giữa các từ với nhau. Ví dụ, GPT-3 có thể sinh ra một câu hoàn chỉnh “The animal didn’t cross the street because it was too tired” vì nó hiểu được “it” ở đây ám chỉ từ animal và không phải street. Chỉ số attention score này được tạo nên từ các vector biểu thị ngữ cảnh (context), và độ quan trọng của các từ trong một văn bản.
Cụ thể hơn, mạng Transformer bên trong GPT-3 có cấu trúc như sau:
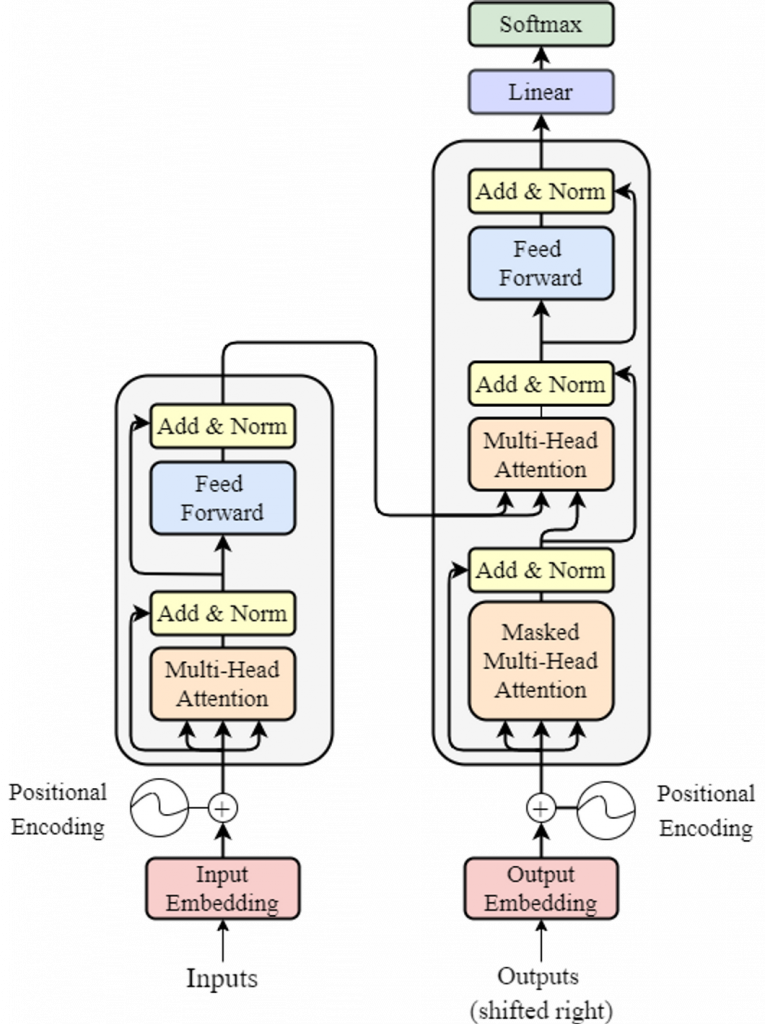
Hình 4. Cấu trúc mạng Transformer của GPT-3
Trong đó bộ mã hóa (encoder) có nhiệm vụ phân tích, và đọc hiểu văn bản, cùng với bộ giải mã (decoder) giúp tạo ra văn bản sau các bước xử lí. Bên trong bộ encoder và decoder này là các lớp multi-head attention với nhiệm vụ tính toán attention score.
Huấn luyện SFT model bằng GPT-3
Để thực hiện fine-tuning cho GPT-3, đầu tiên, dữ liệu được thu thập từ rất nhiều nguồn khác nhau trên Internet [4]. Đây đều là những nguồn dữ liệu đáng tin cậy đã được kiểm chứng. Tổng cộng có 570GB dữ liệu bao gồm thông tin từ các đầu sách, website, Wikipedia, các bài báo khoa học và những bài đăng trên Internet.
Nguồn dữ liệu này sau đó sẽ trở thành input cho GPT-3 để model này generate ra nhiều các output tương ứng, với sự chính xác và phù hợp hơn, giúp cải thiện performance của GPT-3. Nói cách khác, mục tiêu của bước này là giúp model có thể dự đoán từ tiếp theo sẽ được sinh ra trong một văn bản dựa vào những từ trước đó. Để hiểu hơn qui tắc sinh văn bản của GPT-3, ta quan sát minh họa dưới đây:

Hình 5. Minh họa quá trình sinh văn bản của GPT-3
Giả sử ta có input cho GPT-3 là một câu hỏi “What’s for breakfast?”, kí hiệu là u, lúc này GPT-3 sẽ sinh ra câu trả lời theo từng từ một. Đầu tiên, GPT-3 sẽ generate ra từ “Today”, sau đó từ này cùng với câu hỏi u ban đầu sẽ tiếp tục trở thành input cho vòng lặp sau để sinh ra từ “we”, và hai từ đã sinh ra lại tiếp tục cùng với u trở thành input để sinh ra các từ tiếp theo.
Để chọn được các từ một cách chính xác và tạo thành một câu trả lời hoàn chỉnh, GPT-3 sẽ tính xác xuất của từng từ trong bộ từ điển mà nó được huấn luyện để dự đoán từ tiếp theo cần được điền vào. Dựa vào bảng xác suất dưới đây ta có thể biết được từ cuối cùng mà GPT-3 cần chọn để hoàn thiện câu trả lời của nó chính là từ “Toast”, do từ này có xác suất cao nhất trong tất cả các kết quả mà GPT-3 có thể dự đoán.
| Từ | Xác suất |
| Fries | 0.07 |
| Toast | 0.31 |
| Bread | 0.19 |
Quá trình “tái huấn luyện” GPT-3 kết thúc và tạo nên GPT-3.5. Vì được fine-tuning từ một supervised model, nên GPT-3.5 còn được gọi là SFT model (supervised fine-tuned model)
Bước 2: Huấn luyện Reward model
SFT model ở bước 1 sẽ được tiếp tục sử dụng trong bước 2 để huấn luyện mô hình đánh điểm (reward model – RM). Để huấn luyện được mô hình này, OpenAI đã sử dụng kết hợp các kết quả được sinh ra từ SFT model, cùng với các đánh giá được thực hiện bởi con người, để tạo nên một mô hình RM có khả năng ranking các câu trả lời với các tiêu chí đúng sự thật, không chứa các ngôn từ thù ghét và chân thật như một con người. Cụ thể hơn, quá trình huấn luyện RM được thực hiện theo các bước sau:
- Tạo ra các câu trả lời khác nhau cho cùng một câu hỏi
- Con người can thiệp vào để đánh điểm các câu trả lời được sinh ra theo các tiêu chí kể trên
- Sử dụng các cặp (câu trả lời, điểm) được sinh ra ở hai bước trên làm dữ liệu huấn luyện RM.
Tạo ra dữ liệu để huấn luyện reward model
Ở bước này, một tập các output khác nhau sẽ được tạo nên do chính SFT model sinh ra. Để SFT model có thể sinh ra nhiều câu trả lời cho cùng một câu hỏi u như ví dụ ở phần trước, các bộ decoder sẵn có bên trong cấu trúc Transformer của GPT-3.
Ví dụ với cùng câu hỏi u “What’s for breakfast?”, ta sẽ có 4 câu trả lời khác nhau tùy vào bộ decoder được sử dụng trong mỗi vòng lặp huấn luyện như sau:
| Câu trả lời | Bộ decoder tương ứng |
| “Today we will have French eggs” | Nucleus sampling |
| “Today we will have French fries” | Temperature sampling |
| “Today we will have French bread” | Top-K sampling |
| “Today we will have French toast” | Greedy sampling |
Trong đó, quy tắc tính toán xác suất các từ tiếp theo được dự đoán của mỗi bộ decoder như sau:
- Nucleus sampling: sử dụng một tham số p cho trước và chọn ra những từ sao cho tổng xác suất lớn hơn ngưỡng p.
- Temperature sampling: sử dụng một tham số t để kiểm soát mức độ đa dạng của output.
- Top-K sampling: sử dụng tham số k được dùng để lấy top k phân phối đại diện cho từ tiếp theo.
- Greedy sampling: chọn từ có xác suất cao nhất làm output.
Con người can thiệp để đánh giá các câu trả lời
Sau khi đã có 4 câu trả lời với cùng một câu hỏi u, 4 câu trả lời này sẽ được con người (labeler) đánh giá và cho điểm để tìm ra câu trả lời phù hợp nhất theo các tiêu chí của user.
Việc đánh nhãn cho các câu hỏi của user được thiết kế như ảnh dưới đây, trong đó phần đánh giá gồm 2 mục là tính score cho câu hỏi từ 1 (thấp nhất) đến 7 (tốt nhất) và bộ câu hỏi kiểu Yes/No dành cho câu trả lời đang cần đánh giá. Dựa theo kết quả trên, ta có thể thống kê chính xác câu trả lời dành cho câu hỏi có gần với ý muốn của người dùng hay chưa.
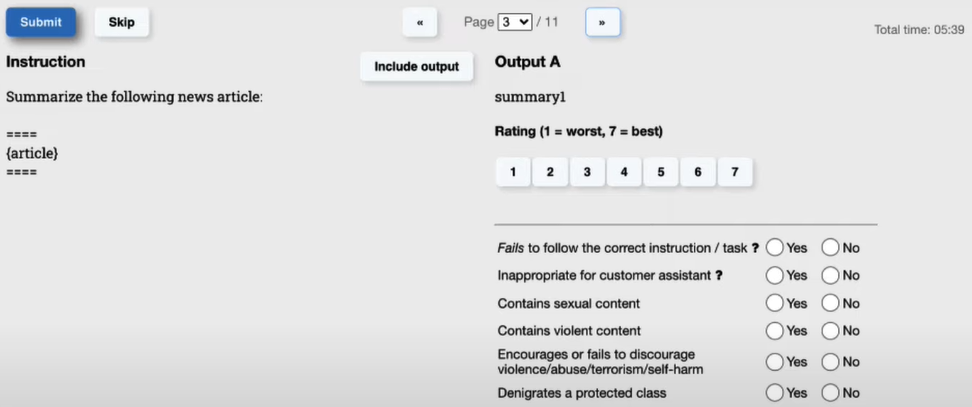
Hình 6. Con người đánh giá các câu hỏi được SFT model sinh ra
Thường trọng số của phần đánh giá dựa trên các tiêu chí Yes/No đóng vai trò cao hơn so với score từ 1-7. Có thể nhận thấy, việc chấm điểm theo score và theo các tiêu chí Yes/No hoàn toàn phụ thuộc vào cảm tính của từng labeler khác nhau, và có thể tạo nên rất nhiều kết quả khác nhau, lí giải cho việc các câu trả lời của ChatGPT có phần gần gũi và tự nhiên như câu trả lời của một con người.
Toàn bộ quá trình huấn luyện RM vừa trình bày được minh họa trong hình dưới đây:
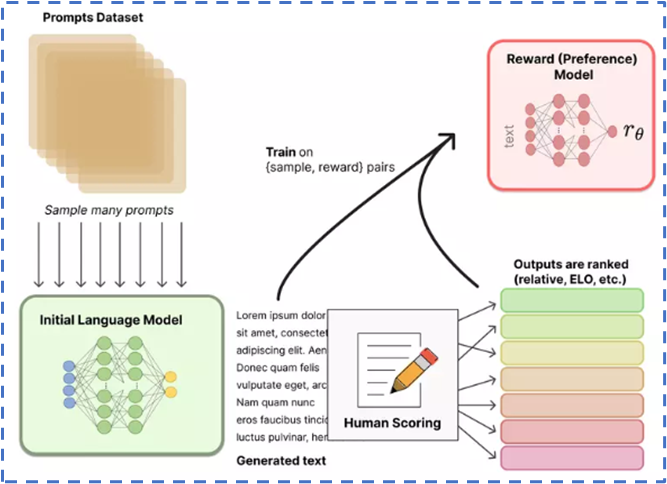
Hình 7. Bước 2 của thuật toán RLHF
Các khái niệm cơ bản của học tăng cường
Để có thể hiểu rõ được bước cuối cùng trong thuật toán RLHF, ta cần nắm một số khái niệm cơ bản của học tăng cường. Các khái niệm này có thể được minh họa thông qua trò chơi Frozen Lake dưới đây.

Figure 8. Minh họa học tăng cường bằng game Frozen Lake
Luật chơi như sau, có một chú bé phải tìm cách vượt qua con sông băng giá để đến được với hộp quà. Chú bé có thể tiến/ lùi/ sang trái/ sang phải, đây được gọi là các action. Mỗi lần thay đổi action, chú bé sẽ có một vị trí (state) mới. State mới này có thể khiến chú bé bị rớt xuống hồ cá tra băng giá, hoặc bình an vô sự để cuối cùng đạt được con vịt quay đặt trong hộp quà.
Tùy vào ô vừa chọn mà chú bé sẽ nhận được một reward tương ứng. Ví dụ đi vào ô bình thường sẽ được +1 điểm, rớt xuống hồ sẽ bị -10 điểm và được hộp quà sẽ +100 điểm. Nhiệm vụ của bất kì bài toán học tăng cường nào đều là tối ưu cách mà cậu bé đưa ra hành động (policy) để đạt được tổng phần thưởng cao nhất. Quá trình trên được minh họa bằng vòng lặp Markov-Decision Process (MDP), được xem là tiền đề của các thuật toán học tăng cường.
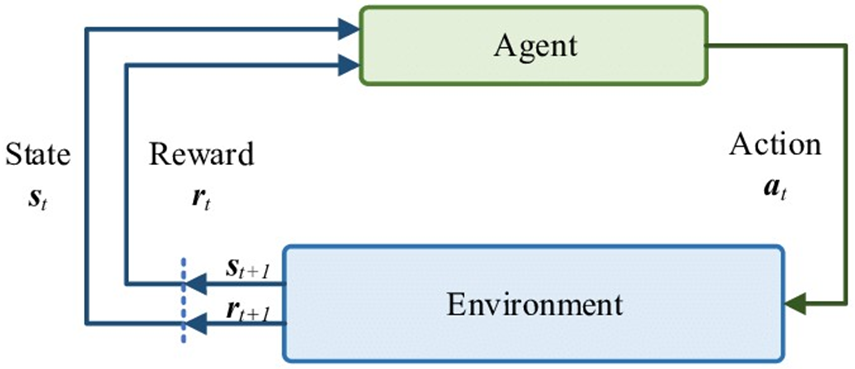
Hình 9. MDP của thuật toán học tăng cường
Bước 3: Tối ưu hóa policy
Cuối cùng, sau khi đã có được SFT model và reward model, phương pháp tối ưu PPO (proximal policy optimization) sẽ được thực hiện, với mục đích cân bằng câu trả lời của ChatGPT giữa nguồn kiến thức có sẵn (ở bước 1) và những đánh giá của con người (ở bước 2). Quá trình này được thực hiện như mô tả trong hình dưới đây:
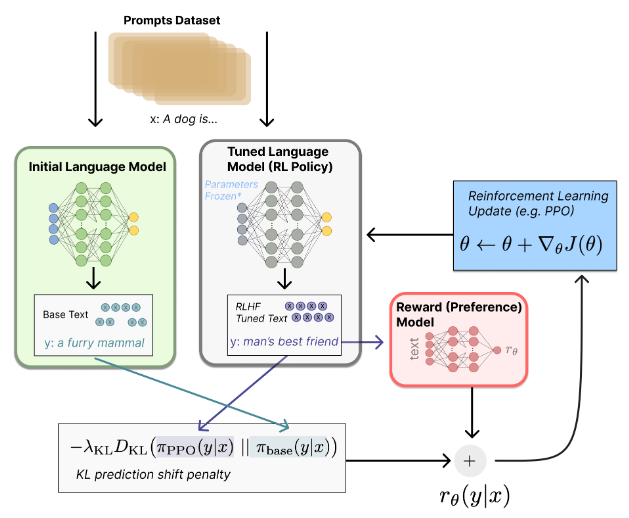
Hình 10. Bước 3 của thuật toán RLHF
Nói cách khác, hai model ở bước 1 và bước 2 sẽ được tinh chỉnh trong bước 3 thông qua quá trình sau:
- Một prompt mới (unseen prompt – một sample chưa từng được sử dụng trong bước 1 và 2) được cùng lúc đưa vào SFT model (kí hiệu trên hình là Initial Language Model) và một bản copy của nó (Tuned Language Model – Tuned-LM). Trong vòng lặp huấn luyện đầu tiên, Tuned-LM được khởi tạo với các thông số giống như SFT model. Trên hình, prompt được minh họa là một đoạn “a dog is…”, kí hiệu là x.
- Khi prompt x đi vào nhánh bên trái, SFT model sẽ trả về kết quả là một response “a furry mammal”, kí hiệu là y. Kết quả y ứng với prompt đầu vào x được tạo nên nhờ một policy . “Base” có nghĩa là policy này sẽ được cố định trong quá trình huấn luyện ở bước 3, do chỉ sử dụng một SFT model với các thông số đã được cố định sau kết quả ở bước 1.
- Khi prompt x đi vào nhánh bên phải, tuned-LM cũng sẽ trả về một kết quả y là một response khác với y ở (2), trên hình minh họa là “man’s best friend”. Kết quả y ứng với prompt x thông qua tuned-LM được tạo nên nhờ policy . Đây chính là policy cần được tinh chỉnh qua các vòng lặp huấn luyện nhờ vào phương pháp tối ưu hóa policy Quá trình ở bước này chính là vòng lặp MDP trong các thuật toán học tăng cường đã được nhắc đến ở bước 2.
- Ngoài ra, kết quả y ở (3) cũng sẽ được đi qua Reward Model đã được huấn luyện ở bước 2 để mô hình này đánh điểm số cho câu trả lời y của tuned-LM. Điểm số do Reward Model đánh cho response y của tuned-LM kí hiệu là , với là trọng số sẽ được cập nhật ngược lại vào tuned-LM (ở bước (5) của quá trình này).
- Từ các bước trên, reward mà thuật toán RLHF đánh giá cho các response y của SFT model và tuned-LM là:
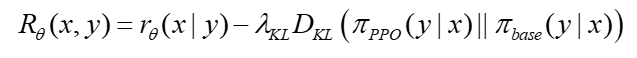
Phương trình trên là hàm cập nhật của thuật toán PPO, được xây dựng dựa trên hội tụ Kullback – Leibler (Kullback – Leibler Divergence). Cụ thể hơn:

Nhờ hội tụ KL mà các reponse được sinh ra từ SFT model và tuned-LM sẽ không khác biệt quá nhiều, giúp cân bằng giữa những kiến thức đã học được ở bước 1 và quá trình đánh giá, tinh chỉnh của con người ở bước 2.
Tổng kết
Từ những phân tích trên, có thể nhận thấy những nội dung mà ChatGPT trả lời đến người dùng được chắt lọc từ những nguồn kiến thức đáng tin cậy, bên cạnh sự tinh chỉnh và đánh giá của con người. Sự kết hợp này đã mang đến thành công cho ChatGPT như hiện tại. Trong tương lai, ChatGPT sẽ còn được phổ biến rộng rãi trên toàn thế giới, với các gói thiết kế phù hợp với người dùng cá nhân hoặc doanh nghiệp dành cho các mục đích khác nhau [2].
Quay lại câu hỏi hóc búa được đặt ra từ đầu bài viết, liệu ta có thể tin tưởng câu trả lời của ChatGPT được hay không? Câu trả lời chắc chắn là có, tuy nhiên, dù được xem là siêu chatbot thông minh nhất tính tới hiện tại, ChatGPT vẫn đang được xây dựng trên nguồn kiến thức có sẵn và chưa thể mô phỏng được khả năng tư duy và sáng tạo của con người.
Một ngày nào đó, rất có thể ChatGPT sẽ đạt đến cảnh giới cao nhất và học được toàn bộ nguồn kiến thức của nhân loại, nhưng nó vẫn sẽ không thể “học” được cảm xúc, sự cảm thông và các chuẩn mực đạo đức khác – thứ tạo nên loài người chúng ta.
TÀI LIỆU THAM KHẢO
[1] https://vnexpress.net/openai-can-bao-nhieu-tien-van-hanh-chatgpt-moi-ngay-4566175.html
[2] https://vnexpress.net/chatgpt-dat-100-trieu-nguoi-dung-ra-ban-thu-phi-4565818.html
[3] https://openai.com/research/instruction-following
[4] https://www.sciencefocus.com/future-technology/gpt-3/
[5] https://vnexpress.net/sieu-ai-gpt-3-ai-khong-tieu-diet-loai-nguoi-tin-toi-di-4159509.html
[6] https://openai.com/blog/openai-baselines-ppo/
[7] https://viblo.asia/p/rlhf-va-cach-chatgpt-hoat-dong-3RlL5AEmLbB
[8] https://www.youtube.com/watch?v=NpmnWgQgcsA
[9] https://www.youtube.com/watch?v=HBZZS96YpaM
[10] https://www.youtube.com/watch?v=_MPJ3CyDokU&t=653s