Mở đầu
Kể từ khi các Convolutional Neural Network (CNN) đầu tiên được tạo ra, các task về computer vision(CV) đã cải thiện đáng kể hiệu suất.
Vào năm 2015, Microsoft đã cho thấy model của họ còn tốt hơn so với con người trong việc phân loại hình ảnh từ dataset ImageNet. Ngày nay, máy tính không có đối thủ khi sử dụng hàng tỷ hình ảnh để giải quyết một nhiệm vụ cụ thể nào đó. Tuy nhiên, trong thực tế, hiếm khi chúng ta có thể xây dựng hoặc tìm thấy một dataset có nhiều mẫu như vậy.
Làm thế nào để chúng ta khắc phục vấn đề này? Nếu chúng ta đang nói về một task CV, chúng ta có thể sử dụng Data augmentation (DA) hoặc thu thập nhiều data hơn nữa. Với tập dữ liệu nhỏ, cả hai kỹ thuật này có thể không giúp ích gì cho chúng ta.
Ví dụ, có một dự án mà chúng ta cần xây dựng một model classification chỉ với 1 hoặc 2 mẫu cho mỗi lớp và mỗi mẫu đều rất khó tìm. Với vấn đề như thế này, đã dẫn đến các nghiên cứu mới hơn, Few-Shot Learning (FSL) là một trong các nghiên cứu đó.
Trong bài blog này, chúng ta sẽ đi qua:
- Few-Shot Learning là gì? Định nghĩa, mục đích và ví dụ về FSL.
- Các biến thể của FSL.
- Các phương pháp của FSL.
- Tìm hiểu về Meta-learning.
- FSL trong Object Detection.
Nội dung chính
Few-Shot Learning là gì?
FSL là việc học một dữ liệu mới khi ta chỉ có một vài mẫu data được label.
Ví dụ: trong lĩnh vực y tế chúng ta thường gặp khó khăn trong việc phát hiện các bệnh về xương thông qua ảnh chụp X-quang. Với một số bệnh lý hiếm gặp có thể sẽ bị thiếu ảnh để sử dụng cho việc training model. Và đây là lúc chúng ta cần FSL.
Các nhà nghiên cứu đã phân FSL thành 4 loại:
- N-Shot Learning (NSL)
- Few-Shot Learning (FSL)
- One-Shot Learning (OSL)
- Zero-Shot Learning (ZSL)
Khi nói về FSL, chúng ta thường nghĩ đến N-way-K-Shot.
- N là số class,
- K là số lượng mẫu từ mỗi class dùng để training.
N-Shot Learning (NSL) được xem như là một khái niệm tổng quát hóa. Few-Shot, One-Shot, Zero-Shot Learning là các trường hợp đặc biệt của NSL.
Zero-Shot
Mục tiêu của Zero-Shot Learning là phát hiên các class chưa được đi qua training.
Chúng ta có thể tưởng tượng như là có thể phát hiện một object mà thậm chí không cần nhìn thấy nó không? Nếu chúng ta có những khái niệm về một object như là diện mạo, thuộc tính và chức năng của nó, thì đó không phải là vấn đề với con người.
One-Shot và Few-Shot
Với One-Shot Learning chúng ta chỉ có một mẫu duy nhất của mỗi class trong lúc training. Few-Shot thì có từ 2 đến 5 mẫu cho mỗi class
Khi nói về khái niệm tổng quát, chúng ta thường sử dụng thuật ngữ FSL. Nhưng lĩnh vực này còn khá mới nên các nhà nghiên cứu có thể sử dụng các thuật ngữ khác. Nhưng ý tưởng chung vẫn sẽ là FSL.
Few-Shot learning approaches
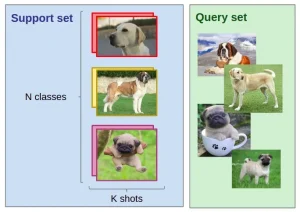
Cùng hiểu rõ hơn về N-way-K-Shot-classification. Hãy tưởng tượng rằng chúng ta có:
- Một bộ đào tạo (support-set) bao gồm:
- N số lượng class
- K số lượng labels cho từng lớp (số lượng ít, dưới mười mẫu/lớp)
- Q ảnh cần chạy detect.
Task cần thực hiện là phân loại Q hình ảnh trong N lớp. Với số lượng data rất ít (N*K) cho tập train, thì vấn đề ở đây là không đủ dữ liệu để training model.
Bước đầu tiên trong FSL là tích lũy kinh nghiệm từ các cách xử lý vấn đề tương tự. Đây là lý do tại sao FSL được mô tả như là Meta-Learning.
Trong một bài toán truyền thống, chúng ta cố gắng học cách phân loại từ training dataset và đánh giá bằng cách sử dụng testing dataset. Trong Meta-Learning, chúng ta “learn how to learn” từ một training dataset, dataset này là tập hợp các class không phải là các class trong bài toàn mình đang giải quyết.
Có hai cách tiếp cận để giải quyết bài toàn bằng cách sử dụng FSL :
- Data-level approach (DLA)
- Parameter-level approach (PLA)
Data-level approach
Cách tiếp cận này dựa trên khái niệm: nếu bạn không có đủ dữ liệu để xây dựng một model đáng tin cậy và để tránh overfitting/underfitting thì bạn chỉ cần thêm nhiều dữ liệu hơn.
Chúng ta cũng có thể tự tạo ra nhiều dữ liệu hơn bằng cách sử dụng Data augmentation (DA) hoặc Generative adversarial networks (GANs).
Parameter-level approach
Với data khá ít nên việc overfit khi train model rất dễ xảy ra. Để khắc phục vấn đề này, chúng ta cần giới hạn parameter space hoặc regularization hoặc sử dụng các hàm loss một cách cẩn thận hoặc kết hợp các phương pháp này. Kết quả là chúng ta có một model tổng quát hơn, không bị overfitting trên tập data nhỏ.
Ngoài ra, chúng ta cũng có thể nâng cao hiệu suất của model bằng cách sử dụng standard optimization, điều này làm cho model bớt đáng tin hơn, nhưng không bị quá overfit.
Tóm lại, với parameter-level là cách tìm đường đi tốt nhất để model có thể học tốt trên tập data hiện tại. Và như được đề cập ở trên, kỹ thuật này được gọi là Meta-learning.
Meta-Learning
Trong các mô hình cổ điển, chúng ta có một task cụ thể, một model sẽ học cách thực hiện task của nó và hiệu suất sẽ được cải thiện theo kinh nghiệm (training model thông thường).
Trong mô hình Meta-Learning, chúng ta có một tập hợp các tasks, một thuật toán sẽ được learning để biết liệu hiệu suất của nó ở mỗi task có cải thiện theo kinh nghiệm và số lượng task được thực hiện hay không. Thuật toán này được gọi là Meta -Learning.
Chi tiết, chúng ta có một task để test (TEST) và chúng ta sẽ training một Meta-Learning của mình trên một loạt các tasks training (TRAIN). Kinh nghiệm train thu được từ việc cố gắng giải quyết các tasks TRAIN sẽ được sử dụng để giải quyết task TEST.

Trong những năm gần đây, các nhà nghiên cứu đã công bố nhiều thuật toán Meta-Learning để giải các bài toán phân loại FSL. Có thể chia thành hai nhóm: Metric-Learning và Gradient-Based Meta-Learning.
Metric-Learning
Khi chúng ta nói về Metric-Learning, chúng ta thường đề cập đến kỹ thuật học một distance function trên các object. Trong trường hợp Few-Shot, model detect các mẫu test dựa trên sự giống nhau của chúng với các mẫu train. Tương tự như chúng ta train một Convolutional Neural Network để trích xuất ra một vector của ảnh, vector này sau đó được so sánh với các embeddings khác để dự đoán class cần phân loại.
Gradient-Based Meta-Learning
Đối với cách tiếp cận dựa trên Gradient, chúng ta cần xây dựng meta-learner và base-learner.
Meta-learner là một mô hình học thông qua các episodes, trong khi base-learner là một mô hình được khởi tạo và đào tạo trong mỗi episodes bởi meta-learner. (xem hình bên trên)
Ví dụ, các bước thực hiện của một episode của Meta-training với một số task được xác định bởi support-set N*K và query set Q:
- Chọn một mô hình meta-learning,
- Episode được bắt đầu,
- Khởi tạo base-learner từ meta-learner,
- Training base-learner trên support-set (thuật toán được sử dụng để train base-learner, được xác định bởi meta-learner),
- Base-learner predict trên query set,
- Meta-learner parameters được train trên kết quả của base-learner predict

Few-Shot Object Detection
Sử dụng Few-shot vào object detect, task của chúng ta là phát hiện tất cả các object được yêu cầu trên một ảnh. Một object được phát hiện nếu:
- Biết được tọa độ bbox của object
- Phân loại được object này là gì.
Vậy bây giờ N-way-K-Shot Object Detection sẽ thực hiện:
- Một bộ support-set:
- N class,
- Đối với mỗi class, K ảnh được label với class này.
- Q ảnh được query.
Mục tiêu của chúng ta là detect các object thuộc một trong N lớp đã cho trong ảnh query.
YOLOMAML
Lĩnh vực Few-Shot Object Detection đang phát triển nhanh chóng, nhưng không có nhiều giải pháp hiệu quả. Một giải pháp điển hình là YOLOMAML. YOLOMAML có hai phần kết hợp: YOLO và MAML. YOLOMAML là một ứng dụng đơn giản của thuật toán MAML cho YOLO.
MAML dựa trên khái niệm Gradient-Based Meta-Learning (GBML). Ở phía trên đã đề cập đến, GBML nói về meta-learner có được kinh nghiệm từ việc đào tạo base-model và học dựa trên tất cả các tasks.
Khi có một task mới cần học, meta-learning với kinh nghiệm trước đó của nó sẽ được fine tune bằng cách sử dụng một lượng nhỏ dữ liệu đào tạo mới, và MAML cung cấp một khởi tạo của meta-learner để học nhanh và tối ưu đối với một task mới chỉ với một số bước chuyển đổi nhỏ trong khi vẫn tránh bị tình trạng overfit.
Tổng kết
Bài blog hôm nay chúng ta đã cùng đi qua giới thiệu sơ lược về Few-shot learning, Meta-learning,… Hi vọng bạn có thể học hỏi được gì đó từ bài viết này. Nếu có thắc mắc hoặc góp ý gì thì đừng ngần ngại comment ở phía dưới nhé. Thân ái và quyết thắng.
References
- “Few-Shot Image Classification with Meta-Learning” by Etienne Bennequin
- “Meta-learning algorithms for Few-Shot Computer Vision” by Etienne Bennequin
- “Understanding Few-Shot Learning in Computer Vision: What You Need to Know” by Vladimir Lyashenko
- “Few-Shot Object Detection: A Comprehensive Survey”