Giới thiệu
hello hello hello, mình là Doanh đây….
Bài viết này dành cho:
- Những ai muốn tìm hiểu về chuỗi mô hình YOLO.
Mở đầu
Ở các bài blog trước là Đã quá YOLO ơi và YOLOv1, chúng ta đã đi qua 1 lượt các version của YOLO cũng như chi tiết về YOLOv1. Ở bài viết lần này, chúng ta tiếp tục với bài “đọc paper” tiếp theo – YOLOv2. Bắt đầu thôi nào…
YOLO9000: Better, Faster, Stronger – Joseph Redmon, Ali Farhadi
YOLOv2 và YOLO9000 là 2 mô hình được J. Redmon và A. Farhadi cho ra đời vào năm 2016 trong cùng 1 paper “YOLO9000: Better, Faster, Stronger”. Với kết quả khá tốt ở 67 FPS, YOLOv2 có mAP = 76,8; và với 40 FPS, có mAP là 78,6 trên bộ dữ liệu VOC 2007 tốt hơn các mô hình như Faster R-CNN và SSD (giải quyết được vấn đề nhanh, nhưng còn yếu ở YOLOv1). YOLO9000 có khả năng detect hơn 9000 class khác nhau, đây là con số rất lớn so với các mô hình phát hiện object khác.
Ở paper này, nhóm tác giả cũng đã đề xuất ra một phương pháp mới để tận dụng dataset về classification để sử dụng cho việc phát hiện object. Ngoài ra, tác giả còn đề xuất ra một thuật toán đào tạo kết hợp object detectors dựa trên data classification và data detect.
Dựa trên tên của paper, chúng ta cùng đi qua lần lượt: Better, Faster và Stronger, để tìm hiểu rõ hơn về chi tiết bên trong của mô hình.

Better
Điểm yếu của YOLOv1 là recall thấp (tỉ lệ bắt đủ các object), do đó, YOLOv2 tập trung và cải tiến điếm yếu này. Với xu hướng cải thiện hiệu quả mô hình, thì network cần phải lớn và sâu hơn hoặc kết hợp nhiều network lại với nhau, vấn đề này làm hệ thống đạt hiệu quả độ chính xác tăng lên, nhưng lại làm tốc độ chậm lại. Với YOLOv2, tác giả đã cải tiến để có được độ chính xác cao và tốc độ vẫn nhanh.
Thay vì mở rộng newtwork, YOLOv2 đơn giản hóa network và làm cho việc học data dễ dàng hơn.
Một số cải tiến của YOLOv2 so với phiên bản trước đó YOLOv1 bao gồm:
- Tích hợp batch normalization: Batch normalization giúp tăng tốc độ hội tụ của network và giảm overfitting. YOLOv2 sử dụng batch normalization trong các lớp convolutional để tăng tính ổn định và hiệu quả của network.
- High-Resolution Classifier: YOLOv2 huấn luyện mô hình classification với độ phân giải cao hơn các cách thực hiện trước đây, với size 448*448 và được train với 10 epochs trên data ImageNet, điều này giúp mô hình classification tăng gần 4% mAP.
- Anchor Boxes: Thay vì sử dụng kích thước cố định cho các bounding box (bbox) được detect, YOLOv2 sử dụng anchor boxes để xác định các kích thước bbox được phát hiện.
- YOLOv2 sử dụng một số anchor boxes có kích thước và tỷ lệ khác nhau, mỗi anchor box được gắn với một vùng nhất định trên ảnh đầu vào, và tất cả các anchor box này được đưa qua một lớp convolutional.
- Mỗi anchor box sẽ đưa ra một số lượng predict, bao gồm tọa độ của bbox và xác suất của class được phát hiện. Từ đó, mô hình YOLOv2 có thể tìm ra các vật thể trong ảnh bằng cách so sánh các predict này với các vật thể thực tế. Điều này giúp mô hình phát hiện được các object có kích thước và tỷ lệ khác nhau.
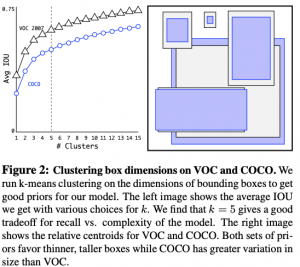
- Dimension Clusters: YOLOv2 sử dụng k-means clustering để xác định các giá trị chiều rộng và chiều cao tối ưu cho các box phát hiện. Điều này giúp giảm số lượng box phát hiện cần phải tính toán và cải thiện hiệu quả của mô hình.
- YOLOv2 sử dụng phương pháp K-means clustering để phân loại các giá trị kích thước bounding box thành các cụm khác nhau. Các giá trị kích thước được chọn được dựa trên các giá trị thực tế của tập dữ liệu huấn luyện. Sau khi phân loại, mỗi cụm sẽ được đại diện bởi giá trị trung bình của các kích thước bounding box trong cụm đó.
- Sau khi đã xác định được các cụm kích thước, YOLOv2 sử dụng các giá trị trung bình của từng cụm để tạo ra các kích thước bounding box tối ưu cho mỗi lớp của object. Điều này giúp YOLOv2 có thể predict các bounding box với độ chính xác cao hơn, đồng thời giảm thiểu số lượng false positives và false negatives.
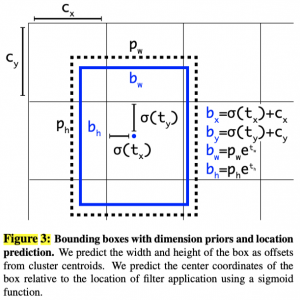
- Direct location prediction: phương pháp này giúp mô hình predict trực tiếp tọa độ của bbox chứa object trên ảnh đầu vào, thay vì sử dụng phương pháp dựa trên anchor box như trong YOLOv1.
- Trong YOLOv2, mỗi class được kết hợp với việc predict bbox chứa object trên ảnh. Thay vì dựa vào anchor box, mô hình YOLOv2 predict trực tiếp 4 giá trị tọa độ (x, y, width, height) cho mỗi bounding box. Mỗi giá trị tọa độ được predict bằng cách sử dụng một lớp tích chập 1×1 và áp dụng logistic activation để đưa ra giá trị từ 0 đến 1.
- Việc predict trực tiếp tọa độ giúp cho mô hình YOLOv2 có thể predict bounding box chính xác hơn và đồng thời giảm thiểu sự phụ thuộc vào anchor box, giúp cho mô hình tổng quan trở nên ổn định hơn trong quá trình huấn luyện.
- Fine-Grained Features: Trong YOLOv1, việc dựđoán object được thực hiện trên một feature map kích thước 13×13. Với feature map này là đủ để predict ra các object có kích thước lớn lớn, nhưng khó để phát hiện các object nhỏ hơn, do khi qua các lớp conv layer, kích thước feature maps ngày càng bị giảm đi, làm mất đi các chi tiết nhỏ. Để giải quyết vấn đề này, YOLOv2 đã lấy thêm một layer trước đó với độ phân giải 26 × 26, với độ phân giải cao hơn này, YOLOv2 đã có thêm các feature từ các layer trước đó. Việc thêm layer này giúp cho việc phát hiện object được thực hiện trên các feature map có độ phân giải cao hơn, từ đó giúp cho việc phát hiện các object nhỏ hơn chính xác hơn.
- Multi-scale training: Để tăng độ chính xác và khả năng phát hiện object của network, YOLOv2 sử dụng multi-scale training. Bằng cách sử dụng nhiều tỉ lệ ảnh khác nhau để đào tạo, YOLOv2 có thể học được đặc trưng của các object có kích thước khác nhau.
- Trong quá trình huấn luyện, YOLOv2 sử dụng các bức ảnh có kích thước ngẫu nhiên trong khoản {320, 352, …, 608}. Điều này đảm bảo mô hình được huấn luyện trên các kích thước khác nhau và cải thiện khả năng phát hiện object nhỏ.
- Khi đưa vào sử dụng, YOLOv2 sử dụng các ảnh có kích thước 416 x 416 để thực hiện phát hiện object. Tuy nhiên, kết quả đầu ra được tính toán từ các feature map được trích xuất từ các ảnh có kích thước khác nhau, từ đó giúp cải thiện khả năng phát hiện object với các kích thước khác nhau.
Faster
Để chạy được các ứng dụng như robotics hay xe tự hành thì việc tốc độ đáp ứng trong thời gian thực (real-time) là rất cần thiết.
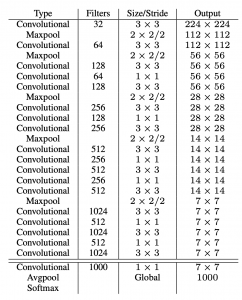
Thay vì tinh chỉnh Googlenet như YOLOv1, thì ở YOLOv2 tác giả đã đề xuất một kiến trúc có tên là Darknet-19 dựa trên kiến trúc VGG. Kiến trúc mạng của Darknet-19 sử dụng chủ yếu các bộ lọc tích chập 3×3 và tăng gấp đôi số kênh sau mỗi lớp pooling. Darknet-19 cũng bao gồm average pooling toàn cục để predict và 1×1 convolutions để nén feature. Batch normalization được sử dụng để ổn định quá trình huấn luyện và tăng tốc độ hội tụ.
So sánh các kiến trúc để thấy được Darknet-19 có tốc độ nhanh hơn, chúng ta cùng nhìn vào bảng bên dưới (nguồn), dễ dàng thấy rằng với hiệu suất cao hơn, nhưng yêu cầu về tính toán thì thấp hơn:

Faster
Xuất phát từ thực tế là có nhiều label hơn cho phân loại hình ảnh so với label của phát hiện object do việc gắn label các object trên hình ảnh để phát hiện object tốn thời gian và khó rất nhiều so với việc dán nhãn cho hình ảnh để phân loại.

Nhóm tác giả đã đề xuất một cách tiếp cận để kết hợp các bộ dữ liệu phân loại và phát hiện object. Redmon và Farhadi gọi mô hình này là YOLO9000 vì nó được training để phát hiện hơn 9000 loại object. Ý tưởng là các label phát hiện object sẽ học các feature dành riêng cho phát hiện object như bbox, score object và phân loại các object phổ biến (trong MS COCO). Ngược lại, những hình ảnh chỉ có label lớp (từ ImageNet) sẽ giúp mở rộng số lượng vật thể mà nó có thể phát hiện.
Conclusion
Trong bài viết, tác giả đã giới thiệu 2 mô hình là YOLOv2 và YOLO9000 dành cho việc phát hiện object trong thời gian thực. Với các cải thiện của YOLOv2 so với YOLOv1, đã góp phần đưa chỗ các kiến trúc YOLO đến gần với ứng dụng trong thực tiễn hơn nữa.
Hi vọng với bài YOLOv2 này đã mang đến cho các bạn thêm một chút kiến thức về chuỗi bài YOLO. Cảm ơn bạn đã đọc đến lúc này. Nếu có bầy kỳ thắc mắc nào thì đừng ngần ngại để lại ở bên dưới comment nhé. Thân!
DoanhPV
#byeCADS
